K-Nearest Neighbors
Overview
Learn the fundamentals of K-Nearest Neighbors (KNN) with step-by-step tutorials, video guides, and practical applications.
Definition
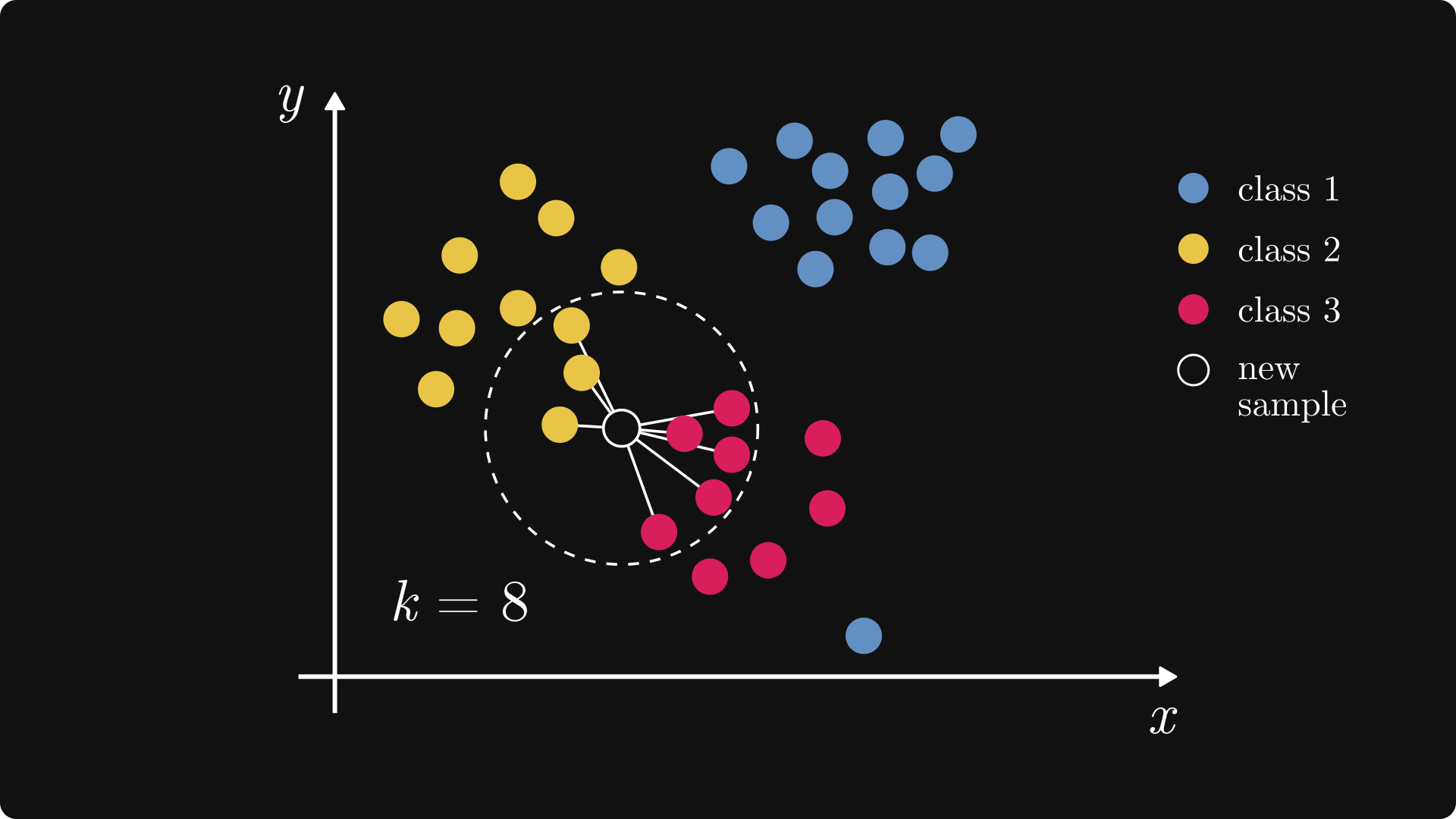
K-Nearest Neighbors (KNN) is a simple, instance-based supervised learning algorithm used for classification and regression. It predicts the output for a new data point based on the majority label or average of its k closest neighbors.
Types / Variants
- Classification: Assigns the class most common among k nearest neighbors.
- Regression: Predicts the average value of k nearest neighbors.
Key Concepts
- Distance Metrics: Euclidean, Manhattan, or Minkowski distance to find nearest neighbors.
- Choosing k: Number of neighbors impacts bias-variance tradeoff.
- Weighted Voting: Closer neighbors can have higher influence on prediction.
- Curse of Dimensionality: Performance can degrade in high-dimensional spaces.
- Lazy Learning: KNN does not train a model explicitly; computations occur at prediction time.
Tutorials
- Implement k-Nearest Neighbors From Scratch
• Step-by-step Python code to build KNN: distance functions, neighbor selection and prediction on Iris dataset.
- k-Nearest Neighbors (kNN) in Python
• Hands-on guide using NumPy and scikit-learn: load data, fit KNeighborsClassifier and tune k.
- KNN Classification with scikit-learn
• Beginner-friendly walk-through: train/test split, model training, prediction, and confusion matrix.
Videos
• Live coding using scikit-learn: load Iris data, fit KNN classifier, make and evaluate predictions.
• Step-by-step implementation: calculate Euclidean distances, choose k, fit neighbors and compute accuracy.
• Hands-on guide: split data, train KNeighborsClassifier, predict labels and visualize results.
Applications
- Classification tasks like handwriting recognition (MNIST) or flower species identification (Iris).
- Regression tasks like predicting house prices using nearby examples.
- Recommendation systems based on similarity of user preferences.
- Anomaly detection by identifying points far from normal clusters.
Resources
Tips & Best Practices
- Normalize or standardize features before applying KNN, as distance metrics are sensitive to scale.
- Experiment with different k values and distance metrics for optimal performance.
- Use weighted voting to give closer neighbors more influence in classification.
- KNN can be slow with large datasets; consider approximate nearest neighbors for efficiency.